|
Other research; some older research directions:
|
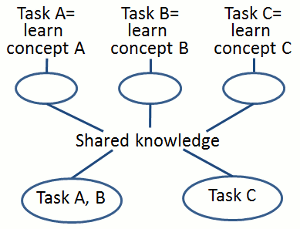
Multi-label and multi-task learning. Exploiting concept correlations is a promising way for boosting the performance of concept detection systems, aiming at concept-based video indexing or annotation. We develop multi-label learning methods, such as an improved method for employing stacked models that captures concept correlations in the last layer of the stack. Besides concept correlations, concept models for different concepts can be related at the feature representation or the task parameters level, i.e, the parameters of the binary classifiers learned from the training data. Motivated by this, we also develop multi-task learning methods that exploit task relations. [mmm14] [tetc15] [icip16a]
| 
|
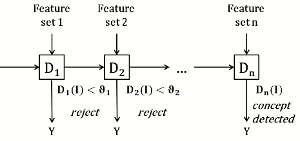
Cascades and other classifier combinations. In image/video annotation problems, we usually have lots of features that we could use, and combining features based on deep convolutional neural networks with other visual descriptors can significantly boost performace. We develop algorithms for efficiently combining multiple features and detectors, such as a subclass recoding error-correcting outputs (SRECOC) method for learning and combining subclass detectors, and a cascade-based algorithm that dynamically selects, orders and combines many base classifiers that are trained independently using different features. [icme13] [icip15a] [mmm16b]
| 
|
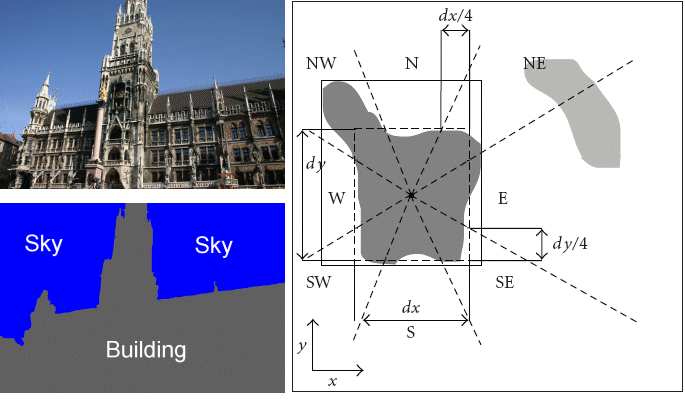
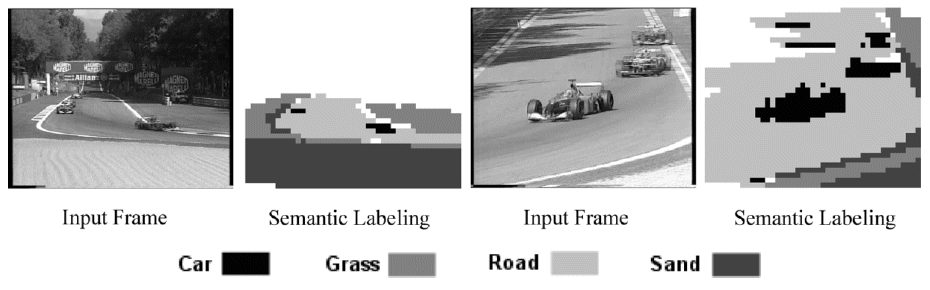
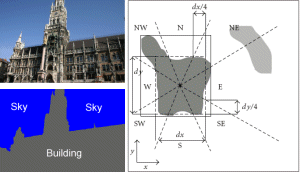
Spatial context for semantic image analysis. We develop and evaluate different approaches to utilizing object-level spatial contextual information (i.e., fuzzy directional relations between image regions) for semantic image analysis. Techniques such as a Genetic Algorithm (GA), a Binary Integer Programming (BIP) and an Energy-Based Model (EBM), are introduced in order to estimate an optimal semantic image interpretation, after classification results are computed using solely visual features. The advantages of each technique are theoretically and experimentally investigated. Evaluations are carried out on six datasets of varying problem complexity. [cviu11]
| 
|
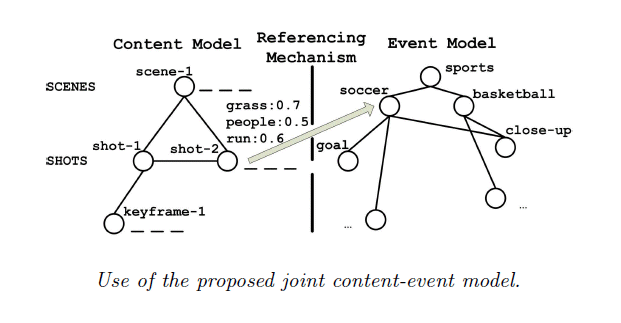
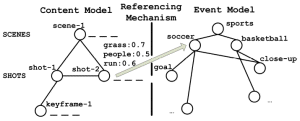
Event-based indexing of multimedia. We develop a joint content-event model for the automatic indexing of multimedia content with events. This model treats events as first class entities and provides a referencing mechanism for automatically linking event elements, represented using the event part of the model, with content segments, described using the content part of the model. The referencing mechanism uses a large number of trained visual concept detectors to describe content segments with model vectors, and the subclass discriminant analysis algorithm to derive a discriminant subspace of this concept space, facilitating the indexing of content segments with event elements. [eimm10] [cbmi11]
| 
|
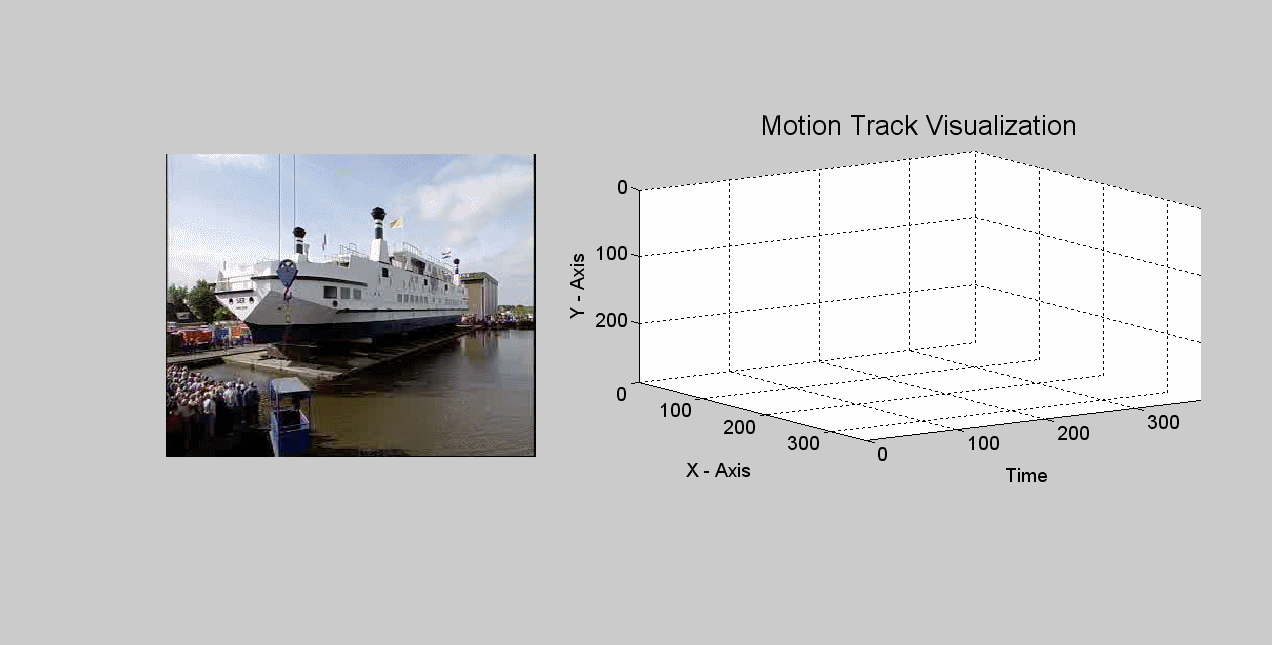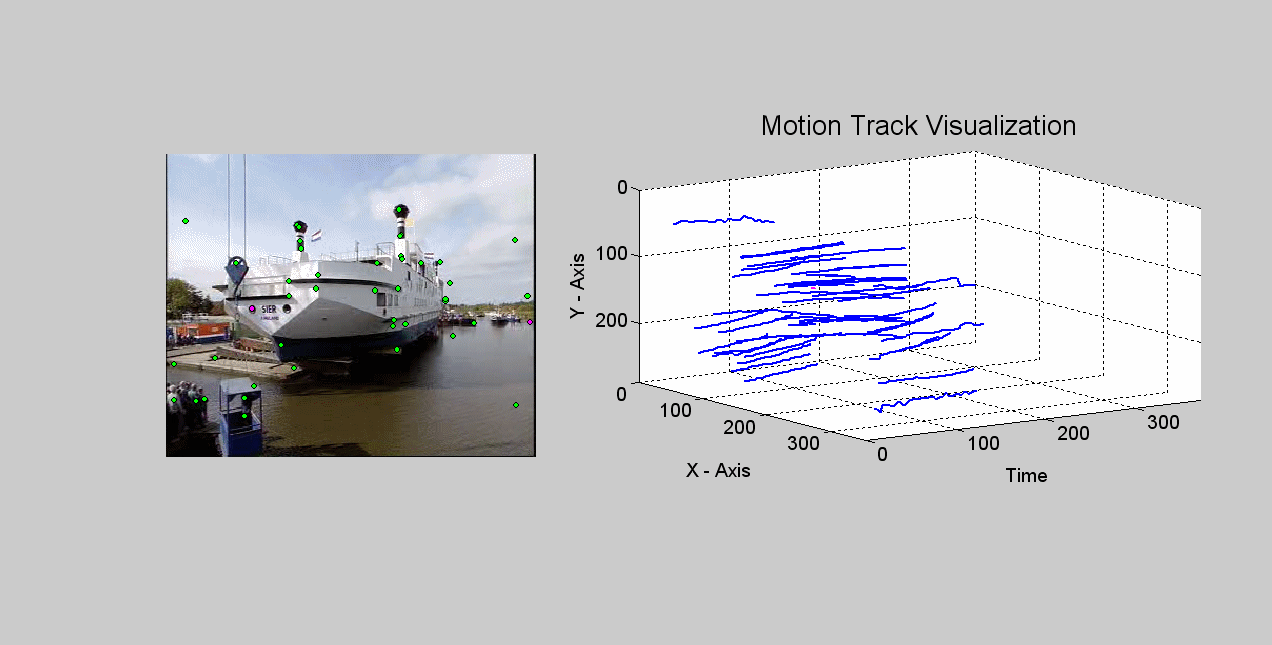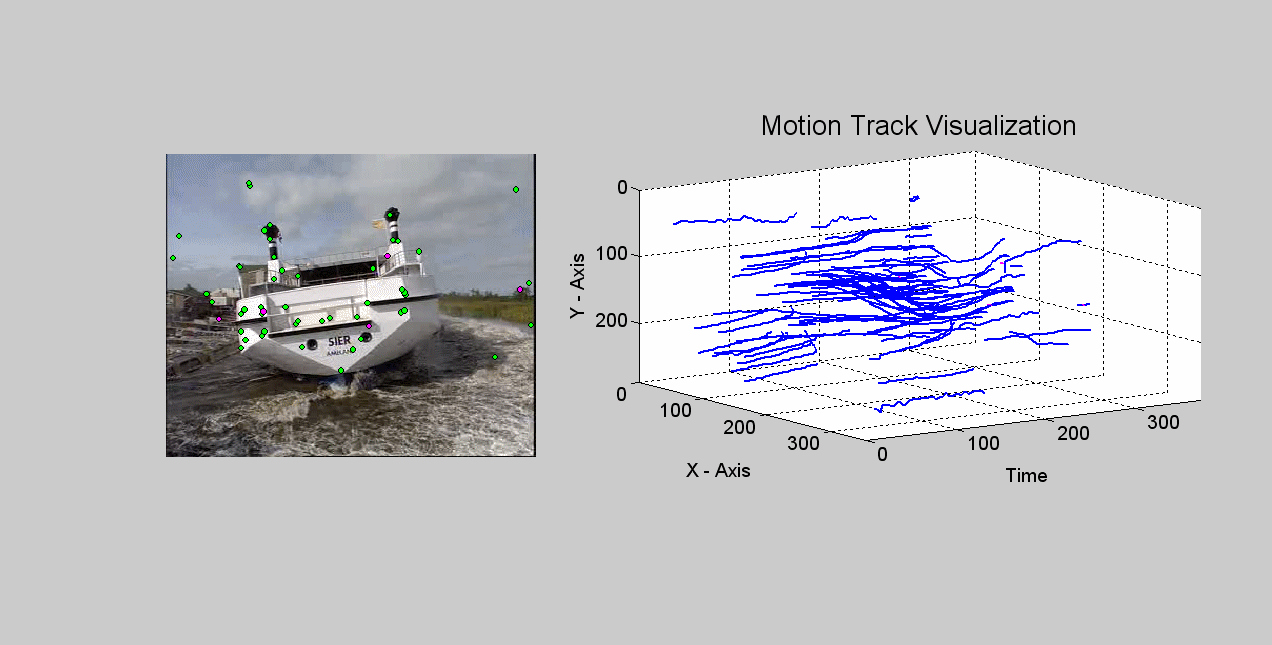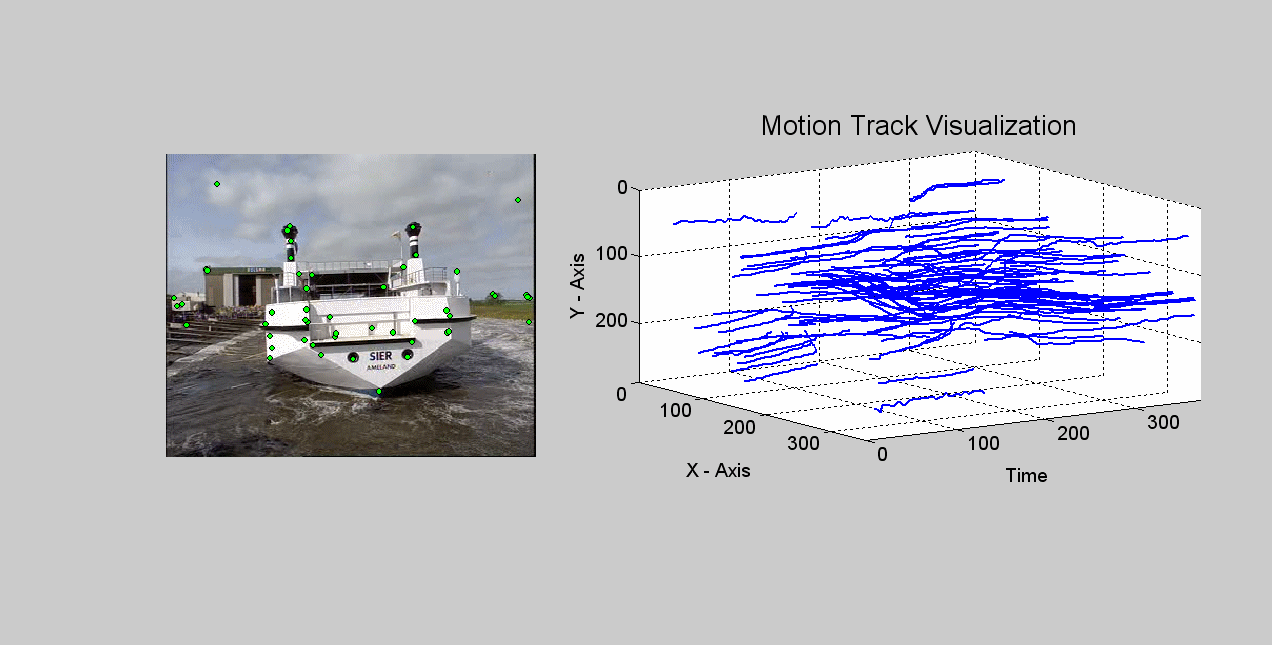
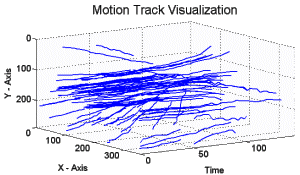
Local Invariant Feature Tracks for concept detection in video. We extract tracks of interest points (a.k.a. "key-point trajectories" or "feature trajectories") throughout the shot and encode each of them using a Local Invariant Feature Track (LIFT) descriptor. This jointly captures the appearance of the local image region and its long-term trajectory. We use the LIFT descriptors of each shot to generate a "Bag-of-Spatiotemporal-Words" model for it, which describes the shot using a vocabulary of "similar in appearance and similarly moving" local regions. [icip10] [watch a track formation example (animated gif, ~8MB)]
| 
|
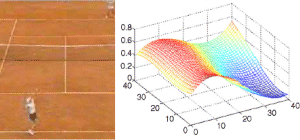
Statistical motion processing for video semantic classification. We use the kurtosis of the optical flow motion estimates for identifying which motion values originate from true motion rather than measurement noise. In this way activity areas are detected, and the motion energy distribution within each activity area is subsequently approximated with a low-degree polynomial function that compactly represents the most important characteristics of motion. This, together with a complementary set of features that highlight particular spatial attributes of the motion signal, are used as input to Hidden Markov Models (HMMs) that associate each shot with one semantic class. [csvt09]
| 
|
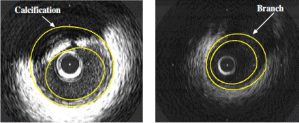
Medical image analysis. We developed fully automated techniques for the detection of the lumen and media-adventitia borders in Intravascular Ultrasound (IVUS) images. Intensity information, as well as the result of texture analysis, generated by means of a multilevel Discrete Wavelet Frames decomposition, are used in two different techniques for contour initialization. For subsequently producing smooth contours, three techniques based on low-pass filtering and Radial Basis Functions are introduced. [ubm08]
| 
|
Ontology-based video analysis and retrieval. We developed a methodology based on real-time video object segmentation, object- and shot-ontologies, as well as a relevance feedback mechanism, enabling object-based retrieval in video collections. We also developed a knowledge-assisted semantic video object detection framework, in which semantic concepts of a domain are defined in an ontology; are then enriched with qualitative attributes, low-level features, spatial relations, and multimedia processing methods; and finally rules in F-logic describe how the multimedia analysis tools should be applied for detecting the ontology concepts. [csvt04a] [csvt05] [mtap06]
| 
|
Spatiotemporal video segmentation. We developed fully automated methods for the segmentation of video to differently moving objects, including a method for the spatiotemporal segmentation of raw video data by exploiting the long-term trajectories of differently moving homogeneous regions, and a method for the real-time spatiotemporal segmentation of MPEG-2 compressed video by exploiting the MPEG-2 motion vectors of I- and P-frames as well as the DC coefficients of DCT-encoded blocks of I-frames. [csvt04a] [csvt04b]
| 
|
Spatial image segmentation. We developed a fully automated method for the fast segmentation of images to spatial regions, for use in object-based multimedia applications such as ontology-based indexing and retrieval. The algorithm operates in the combined intensity texture position feature space, in order to produce connected regions that correspond to the depicted real-life objects. A fast multi-layer processing scheme restricts the iterative part of the segmentation procedure to a low-resolution version of the image, and then derives full-resolution segmentation masks by partial pixel re-classification (watch animation for images zebra, castle). [ijprai04] [jasp04]
| 
|