Vasileios Mezaris
Electrical and Computer Engineer, Ph.D.
| homepage | curriculum vitae | projects | research | demos | downloads | publications | contact | m r d b c p |
| LATEST RESEARCH | OLDER RESEARCH DIRECTIONS |
|
Page contents: - Latest research, from the multimedia analysis perspective: Explainable video event recognition; Video summarization and thumbnail selection; Cross-modal video retrieval; Image/video concept detection and explanation; Image/video quality, aesthetics and forensic assessment; Video spatio-temporal decomposition and object detection; Multimedia organization tools and applications - Latest research, from the AI / machine learning perspective: Explainable AI; Green AI; New deep learning architectures; Learning with uncertainty; Subclass methods for dimensionality reduction and learning | |
|
Latest research, from the multimedia analysis perspective: | |
|
Explainable video event recognition. We develop efficient and explainable methods for recognizing actions/events in video. This involves employing and extending techniques such as graph attention networks and gating mechanisms, or in earlier works our top-performing subclass dimensionality reduction methods and their optimized GPU implementations. We also develop techniques for zero-shot or few-shot event recognition; learning under uncertainty; and AI explainability techniques for explaining the decisions of event recognition networks. [icmr14] [mm15a] [jivc15] [mmm16a] [mm16b] [icmr17b] [cvprw21] [access22]
[ism22b] [ism23]; see also a couple of earlier surveys on events and multimedia: [mtap14] [jivc16] | 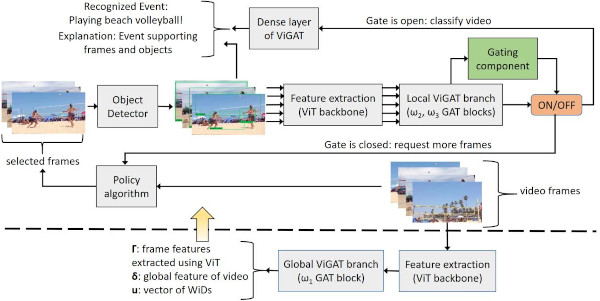
|
|
Video summarization and thumbnail selection. We develop deep learning architectures for automatic and explainable video summarization and thumbnail selection. We focus on architectures based on Generative Adversarial Networks (GANs) or Attention Networks, and we investigate the introduction of new learning mechanisms and training strategies. Our architectures are capable of learning in a fully unsupervised manner, i.e. without ground-truth human-generated video summaries. The resulting trained models can produce representative summaries for unseen videos, exhibiting state of the art performance. [mm19] [mmm20a] [mm20] [csvt21] [icmr21] [ism21a] [icmr22] [ism22c] [icip23] [acmmm23]; see also a survey: [pieee21] | 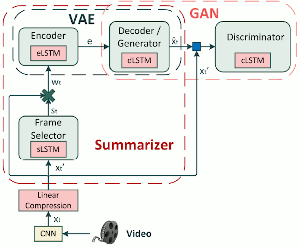
|
|
Cross-modal video retrieval. We develop deep learning techniques for free-text-based video retrieval. We investigate questions such as how to optimally combine diverse textual and visual features for generating multiple joint feature spaces, which encode text-video pairs into comparable representations. We further introduce techniques for revising the inferred query-video similarities, such as softmax operations. Besides the ad-hoc video retrieval problem, we adapt these techniques for related cross-modal problems, such as associating textual news with related images, or zero-shot detection of ad-hoc visual concepts in specific domains. [icmr20] [intap20] [trecvid20] [ht21] [iccvw21] [trecvid21] [eccvw22b] [mediaeval22] | 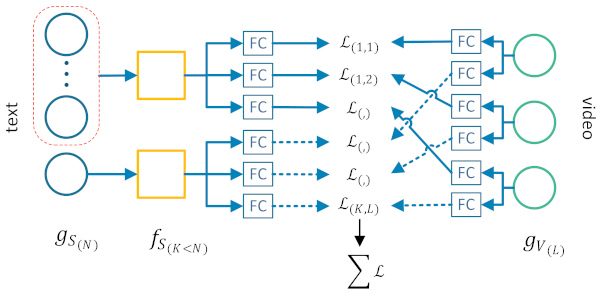
|
|
Image/video concept detection and explanation. We develop efficient and explainable techniques for annotating video fragments with concept labels. For this, we work on machine learning methods coming from the domains of deep learning, multi-task/multi-label learning, dimensionality reduction, and deep network pruning. We also work on AI Explainability techniques, devising new ways to explain the decisions of deep-learning-based image/video concept detectors. We use the concept detection results for content retrieval, or as a stepping stone for e.g. event recognition or video summarization. [csvt14] [tetc15] [icip15a] [mmm16b] [icip16a] [mm16a] [mmm17] [icmr17a] [mm17a] [csvt19] [mmm20b] [icme20] [ism20] [eccvw22a] [ism22a] | 
|
|
Image/video quality, aesthetics and forensic assessment. We develop methods for the assessment of the quality and the aesthetics of visual content. These include features and classification methods for no-reference blur assessment in natural images; using basic rules of photography for aesthetics assessment of natural images; and, features and learning techniques (i.e., learning under uncertainty) for the aesthetic quality assessment of user-generated video. We also assembled and released annotated datasets for facilitating the evaluation of such methods. In addition, we develop methods for the forensic analysis of videos, to understand if a video has been manipulated. [icip14] [icip15b] [icip16b] [mmm19a] [mmm19b] [smap21] [mediaeval2021] | 
|
|
Video spatio-temporal decomposition and object detection. We develop fast and accurate techniques for temporally fragmenting a video to its constituent parts (sub-shots, shots, scenes), often by combining a multitude of low- and high-level audio-visual cues. We use our temporal decomposition methods as the basis for several applications, such as an on-line service for video fragmentation and reverse image search. We also develop techniques for identifying the objects or spatio-temporal regions of interest within the video, to enable applications such as video smart-cropping for video re-purposing and re-use, or face anonymization. [csvt11] [csvt12] [icassp14] [mm17b] [mmm18a] [mmm19d] [icip21] [ism21b] [wacvw24] | 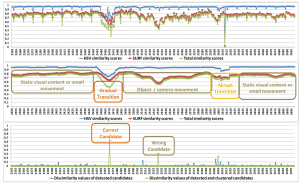
|
|
Multimedia organization tools and applications. We develop techniques and tools for the organization and re-use of multimedia content and for supporting novel applications such as digital preservation and forgetting. These include interactive tools for object re-detection, and automatic techniques for the clustering, summarization and event-based organization of media items, the temporal synchronization and the contextualization of photo collections, social event detection, human-brain-inspired photo selection methods, and video search engines. [icmr14] [icme15a] [icme15b] [icme15c] [mtap15] [mm15b] [mmm16c] [icmr17c] [icmr17d] [mm17b] [mmm18b] [MMmag18] [mmm19c] [mmm19e] [mmm19f] [mmm21] [imx21] [ism21b] [icufn23] [electronics23]; see also a couple of surveys: [mmsj22] [electronics22] | 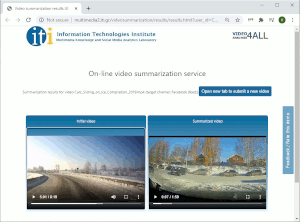
|
|
Latest research, from the AI / machine learning perspective: | |
|
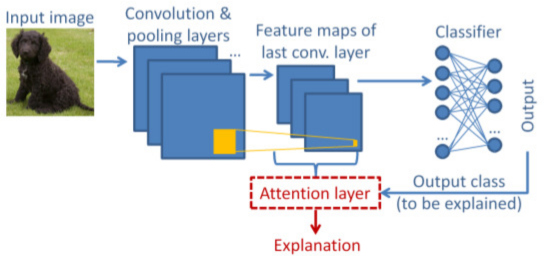
Explainable AI. We develop AI models that produce informative and accurate explanations for their decisions. For example, we introduce attention-like mechanisms in pre-trained image classifiers, to produce explanation maps that highlight the image parts that led to the classifier's decisions; we develop Graph Attention Network architectures for video event recognition, where the specific frames and objects that contribute the most to an event recognition decision are pinpointed; and, we investigate which signals in attention-based video summarizers constitute good explanations for the summarizer's output. [cvprw21] [access22] [eccvw22a] [ism22a]
[ism22b] [ism22c] [acmmm23]
| 
|
|
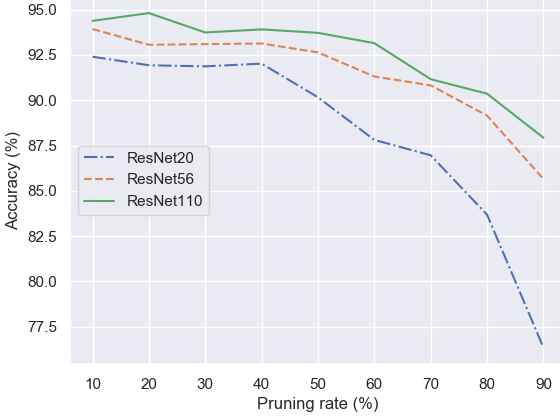
Green AI. We develop techniques for reducing the energy consumption of AI models over their entire lifecycle (training, deployment and use). For example, we build on foundation models (more generally, large pre-trained models) and introduce lightweight learning architectures on top of such models for adapting to downstream tasks such as video event recognition or cross-modal video-text retrieval. We also devise learning architectures that exploit inherent information, such as own explanation signals, to focus on processing just the most informative parts of an incoming video, thus avoiding unnecessary computations; and, we work on deep network pruning techniques, to remove models' unimportant parts. [icme20] [ism20] [cvprw21] [iccvw21] [access22] [eccvw22b] [ism22b] [ism23] [wacvw24]
| 
|
|
New deep learning architectures.
We develop new learning architectures based on Graph Attention Networks, Transformers, Generative Adversarial Networks as well as traditional CNNs and other deep learning paradigms. These include, for instance, pure-attention architectures for bottom-up video event recognition; multiple-space learning approaches for cross-modal video-text retrieval; generative networks and attention-based architectures for unsupervised learning of video summarization and thumbnail selection tasks; transfer learning, multi-task learning, fine-tuning and layer extension strategies to optimize deep-learning-based classifiers. [mm16a] [mmm17] [icmr17a] [icmr17b] [csvt19] [mmm19a] [mmm19b] [mm19] [mmm20a] [mmm20b] [icme20] [icmr20] [mm20] [ism20] [csvt21] [cvprw21] [icmr21] [iccvw21] [ism21a] [icmr22] [access22] [eccvw22b] [ism22b] [ism22c] [icip23]; see also a couple of surveys: [tomm17] [pieee21] | 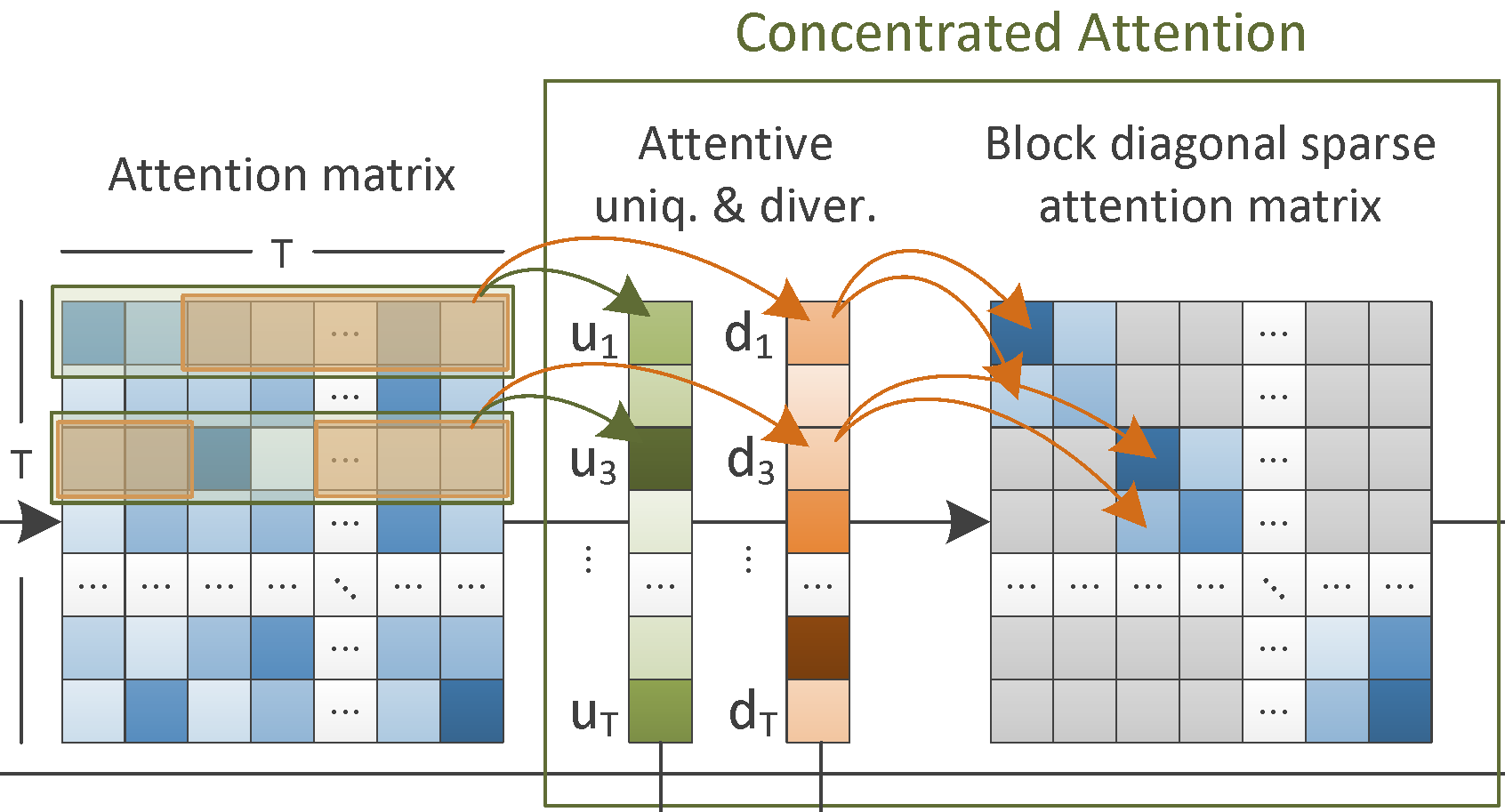
|
|
Learning with uncertainty. We develop linear and kernel-based methods for learning from uncertain data. These are a family of extensions of the Support Vector Machine classifier, which we call Support Vector Machine with Gaussian Sample Uncertainty. They treat input data as multi-dimensional distributions, rather than single points in a multi-dimensional input space. These distributions typically express out uncertainty about the measurements in the input space and their relation to the underlying noise-free data. [mmm16a] [icip16b] [fg17] [pami18] | 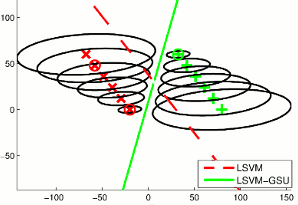
|
|
Subclass methods for dimensionality reduction and learning. We develop very efficient subclass-based dimensionality reduction and learning methods, for dealing with high-dimensional data. These include a linear Subclass Support Vector Machine (SSVM) classifier, and extensions of Subclass Discriminant Analysis, such as the Mixture Subclass Discriminant Analysis (MSDA), Fractional Step MSDA (FSMSDA), Kernel MSDA (KMSDA) and Accelerated Generalised SDA (AGSDA). We also developed an optimized GPU software implementation of our AGSDA method. [spl11] [spl12] [tnnls13] [mm15a] [mm16b] [mm17a] | 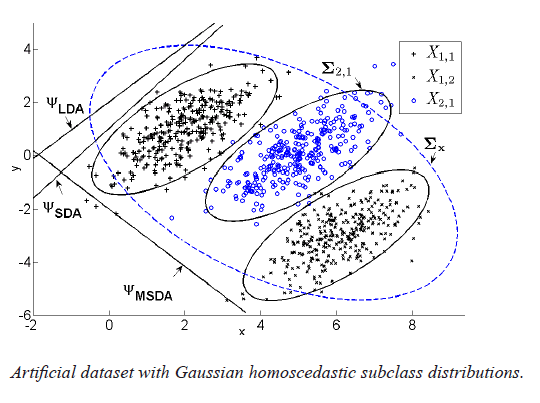
|