Vasileios Mezaris
Electrical and Computer Engineer, Ph.D.
| homepage | curriculum vitae | projects | research | demos | downloads | publications | contact | m r d b c p |
| SOFTWARE | DATASETS |
|
P-TAME: Explain Any Image Classifier with Trained Perturbations.
P-TAME (Perturbation-based Trainable Attention Mechanism for Explanations) is a model-agnostic method for explaining DNN-based image classifiers. It uses an auxiliary image classifier to extract features from the input image, bypassing the need to modify the explanation method so that it matches the specific architecture of the classifier being explained. Unlike traditional perturbation-based methods, P-TAME generates high-resolution explanations efficiently in a single forward pass during inference.
- Related publications [ojsp2025] - Software packages in github: [P-TAME] | 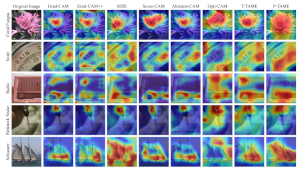
|
|
Multimodal hateful meme detection exploiting LMM-generated knowledge.
We provide code and trained models for our LMM-CLIP and LMM-LongCLIP methods for hateful meme detection. These leverage an LMM in a two-fold manner: for extracting knowledge oriented to the hateful meme detection task, in order to build strong meme representations; and, for introducing a hard mining approach based on LMM-encoded knowledge to the training of the hateful meme detector.
- Related publications [cvprw2025a] - Software packages in github: [LMM-CLIP-meme] | 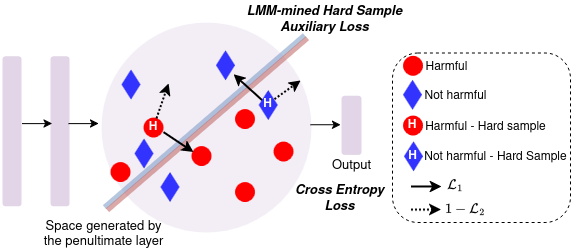
|
|
T-TAME: Transformer-compatible Trainable Attention Mechanism for Explanations. T-TAME is an extension of our earlier TAME method; it is a post-hoc explanation method for both DCNN-based and Transformer-based image classifiers. T-TAME can be easily applied to any such classifier using a streamlined training approach; and, after training, explanation maps can be efficiently computed in a single forward pass. We have tested T-TAME on VGG-16, ResNet-50, and ViT-B-16 classifiers trained on ImageNet.
- Related publications [access24] (see also [ism22a], [eccvw22] for our related earlier TAME and L-CAM methods) - Software packages in github: [T-TAME] | 
|
|
Explainable AI for Deepfake Detection. We provide code, models and data for our method on improving the perturbation-based explanation of deepfake detectors through the use of adversarially-generated samples. We also provide materials for evaluating the performance of five explanation approaches from the literature (GradCAM++, RISE, SHAP, LIME, SOBOL), on explaining the output of a state-of-the-art model (based on Efficient-Net) for deepfake detection.
- Related publications [icmr24b] [wacvw25a] - Software packages in github: [XAI-Deepfakes], [Adv-XAI-Deepfakes] | 
|
|
Pruned Lightweight Face Detectors. We investigate the application of filter pruning on two already small and compact face detectors, EXTD (Extremely Tiny Face Detector) and EResFD (Efficient ResNet Face Detector). We combine Bayesian optimization, for tuning the pruning rate of different parts of the detector's architecture, with a Filter Pruning via Geometric Median (FPGM) algorithm. We show that in this way we can further reduce the model size of already lightweight face detectors, with limited accuracy loss, or even with a small accuracy gain for low pruning rates.
- Related publications [wacvw24] [wacvw25b] - Software packages in github: [FPGM] [B-FPGM] | 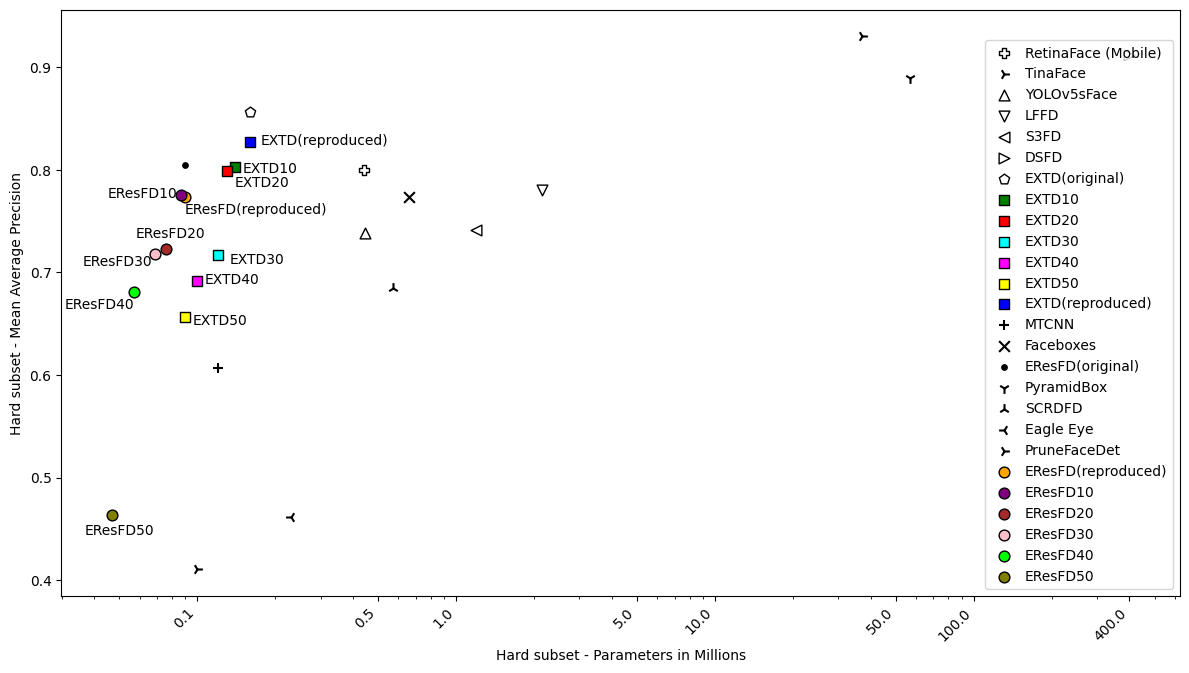
|
|
OAT: Online Anchor-based Training. We improve deep learning models for image classification by proposing an Online Anchor-based Training methodology (OAT). OAT, guided by the insights provided in anchor-based object detection, instead of learning directly the class labels proposes to train a model to learn percentage changes of the class labels with respect to defined anchors. We define as anchors the batch centers at the output of the model. During inference, the predictions are converted back to the original class label space.
- Related publications [icip24b] - Software packages in github: [OAT] | 
|
|
Multi-Modal Fusion for Image Manipulation Detection and Localization. We showcase that different image manipulation filters excel at unveiling different types of manipulations and provide complementary forensic traces. To take advantage of this, we propose two ways for merging the outputs of such filters to perform more accurate image manipulation localization and detection.
- Related publications [mmm24a] [arXiv:2312.01790] - Software package [download source code] | 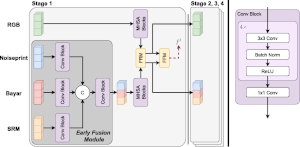
|
|
Detecting Visual-Audio Discrepancies in Video. We provide scripts and trained models for detecting discrepancies in video: uni-modal classifiers that can be applied separately to the audio / visual modality to detect scene-class inconsistencies between them, and a joint audio-visual scene classification model. We also provide a benchmark dataset simulating such audio-visual inconsistencies.
- Related publications [icmr24a] - Software package [download source code] | 
|
|
Spatio-Temporal Summarization of 360-degrees Videos. We combine a camera motion detection method, two saliecy detection methods for generating frame-level saliency maps, a salient event detection approach for extracting traditional 2D+time video volumes from the 360-degrees video, and an adapted state-of-the-art video summarization method, to transform 360-degrees videos to video summaries that are suitable for traditional video distribution channels.
- Related publications [mmm24b] - Software package [download source code] | 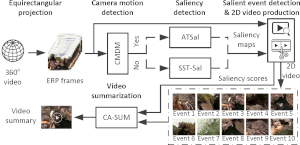
|
|
Masked-ViGAT: Masked Feature Modelling for Video Event Recognition. We introduce Masked Feature Modelling (MFM) for the unsupervised pretraining of a Graph Attention Network (GAT) block. MFM utilizes a pretrained Visual Tokenizer to reconstruct masked features of objects within a video, leveraging the MiniKinetics dataset. We then incorporate the pre-trained GAT block into a state-of-the-art bottom-up supervised video-event recognition architecture, ViGAT, to improve the model's accuracy in a smaller target dataset.
- Related publications [ism23] - Software package [download source code] | 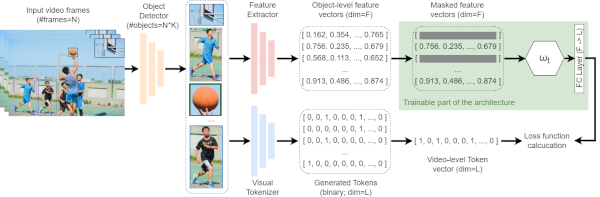
|
|
RL-DiVTS: Selecting diverse, representative and aesthetically-pleasing video thumbnails. RL-DiVTS is a new reinforcement-based method for video thumbnail selection, that relies on estimates of the frames' aesthetic quality, representativeness and visual diversity, made with the help of tailored reward functions. It integrates a novel diversity-aware Frame Picking mechanism that performs a sequential frame selection and applies a reweighting process to demote frames that are visually-similar to the already selected ones.
- Related publications [icip23] - Software package [download source code] | 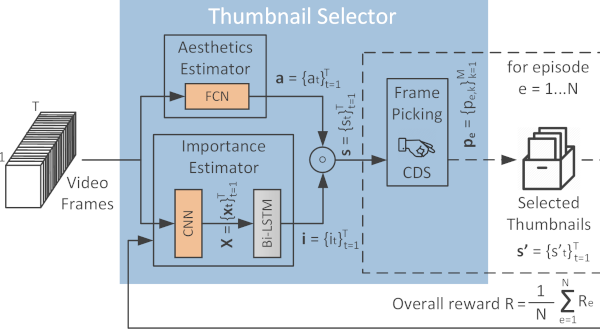
|
|
TAME: Trainable Attention Mechanism for Explanations. TAME is a method for post-hoc explanation of DCNN-based image classifiers. TAME learns to generate explanation maps by introducing a multi-branch hierarchical attention mechanism. This mechanism is trained end-to-end along with the original (frozen) DCNN, to derive class activation maps (CAMs) using the feature maps (FMs) coming from multiple layers of the original DCNN. After training, explanation maps can be computed in a single forward pass.
- Related publications [ism22a] (see also [eccvw22] for a related earlier method) - Software package [download source code] | 
|
|
Gated-ViGAT: Efficient Bottom-Up Event Recognition. Gated-ViGAT combines bottom-up (object) information, a new frame sampling policy and a gating mechanism for video event recognition. The frame sampling policy uses weighted in-degrees (WiDs), derived from the adjacency matrices of graph attention networks (GATs), and a dissimilarity measure to select the most salient and diverse frames. The gating mechanism fetches the selected frames and commits early exiting when an adequately confident decision is achieved.
- Related publications [ism22b] (see also [access22] for a related earlier method) - Software package [download source code] | 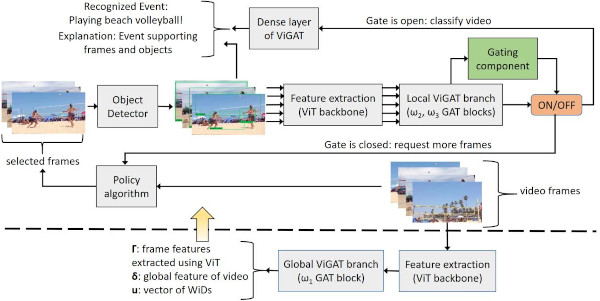
|
|
Explaining video summarization based on the focus of attention. The problem we address is the creation of an explanation mask, which indicates the parts of the video that influenced the most the estimates of a video summarization network about the frames' importance. We examine various attention-based signals and we evaluate their performance in combination with different replacement functions, and utilizing measures that quantify the capability of explanations to spot the most and least influential parts of a video.
- Related publications [ism22c] [acmmm23] (see also [icmr22] for the CA-SUM summarizer that we used as the basis) - Software package [download source code] | 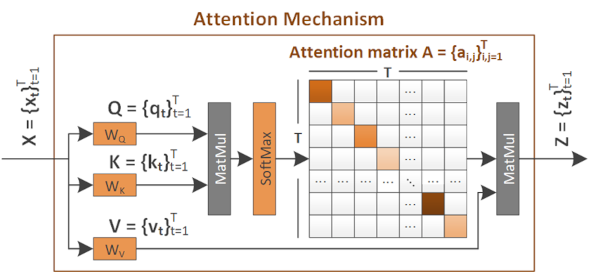
|
|
L-CAM: Learning Visual Explanations for DCNN-Based Image Classifiers. We provide code and associated materials for two learning-based eXplainable AI (XAI) methods, L-CAM-Fm and L-CAM-Img, for DCNN image classifiers. Our methods receive as input an image and a class label and produce as output the image regions that the DCNN has focused on in order to infer this class. Both methods use an attention mechanism (AM), trained end-to-end along with the original (frozen) DCNN, to derive class activation maps (CAMs) from the last convolutional layer's feature maps (FMs).
- Related publications [eccvw22] - Software package [download source code] | 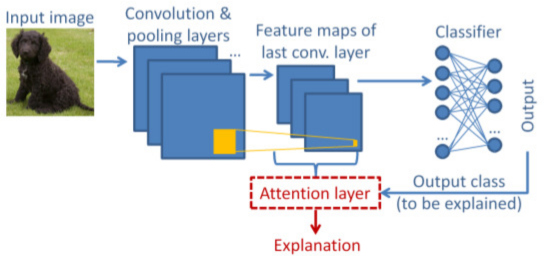
|
|
ViGAT: Video Event Recognition and Explanation. This software can be used for training our deep learning architecture called ViGAT, which utilizes an object detector together with a Vision Transformer (ViT) backbone network to derive object and frame features, and a head network to process these features for the task of event recognition and explanation in video. Our ViGAT method makes unique contributions in the areas of bottom-up event recognition and explainable AI for video understanding.
- Related publications [access22] - Software package [download source code] | 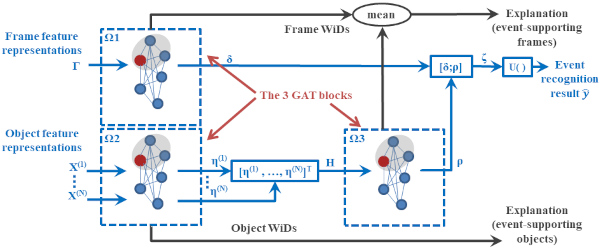
|
|
T-times-V for text-based video retrieval. We provide the implementation of our T-times-V method for free-text-based video retrieval. Our method learns how to combine multiple diverse textual and visual features towards generating multiple joint feature spaces, which encode text-video pairs into comparable representations. It also introduces an additional softmax operation at the retrieval stage, for revising the query-video similarities inferred by the trained network. - Related publications [eccvw22] - Software package [download source code] | 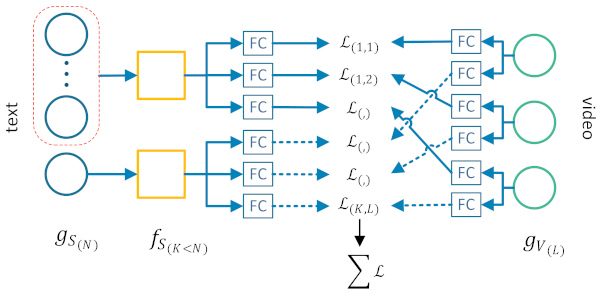
|
|
CA-SUM for Unsupervised Video Summarization. This software can be used for training a deep learning architecture, which estimates frames' importance by integrating a concentrated attention mechanism and utilizing information about the frames' uniqueness and diversity. Training is performed in an unsupervised manner. After being on a collection of videos, the CA-SUM model is capable of producing summaries for unseen videos, according to a user-specified time-budget about the summary duration. - Related publications [icmr22] - Software package [download source code] | 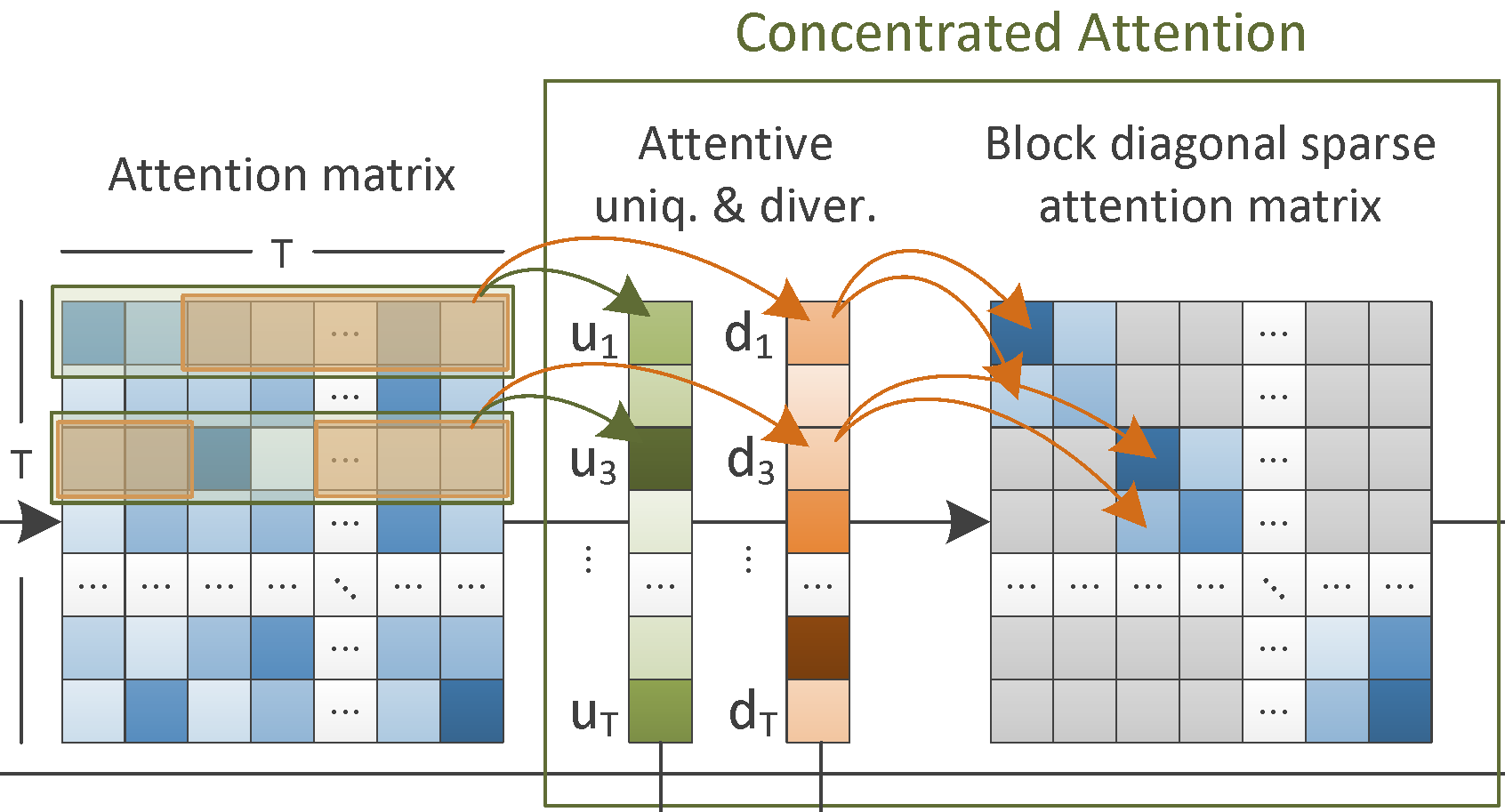
|
|
PGL-SUM for Supervised Video Summarization. This software can be used for training a deep learning architecture which estimates the frames' importance after modeling their dependencies with the help of global and local multi-head attention mechanisms that integrate a positional encoding component. Training is performed in a supervised manner (using human-generated video summaries). After being trained, the PGL-SUM model can produce representative summaries for unseen videos, according to a user-specified time-budget about the summary duration. - Related publications [ism21a] - Software package [download source code] | 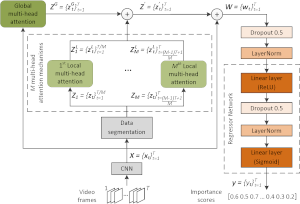
|
|
Video Thumbnail Selector: Combining Adversarial and Reinforcement Learning. This software can be used for training a deep learning architecture for video thumbnail selection, taking under consideration the representativeness and the aesthetic quality of the video frames. Training is fully-unsupervised, based on a combination of adversarial and reinforcement learning. After being trained on a collection of videos, the Video Thumbnail Selector is capable of selecting a set of representative video thumbnails for unseen videos. - Related publications [icmr21] - Software package [download source code] | 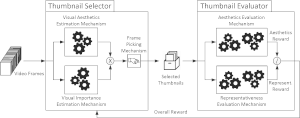
|
|
SmartVidCrop: A Fast Cropping Method for Video Retargeting. This is an implementation of our fast video cropping method, which allows adapting an input video to a different aspect ratio while staying focused on the original video's main subject. Our method utilizes visual saliency to find the regions of attention in each frame, and employs a filtering-through-clustering technique as well as temporal filters to select the main region of focus and produce a smooth sequence of cropped frames. - Related publications [icip21] [ism21b] - Software package [download source code] | 
|
|
ObjectGraphs: Video Events Recognition and Explanation. This is an implementation of ObjectGraphs, our novel bottom-up video event recognition and explanation approach. It combines object detection, a graph convolutional network (GCN) and a long short-term memory (LSTM) network for performing video event recognition as well as for identifying the objects that contributed the most to the event recognition decisions, thus providing explanations for the latter. - Related publications [cvprw21] - Software package [download source code] | 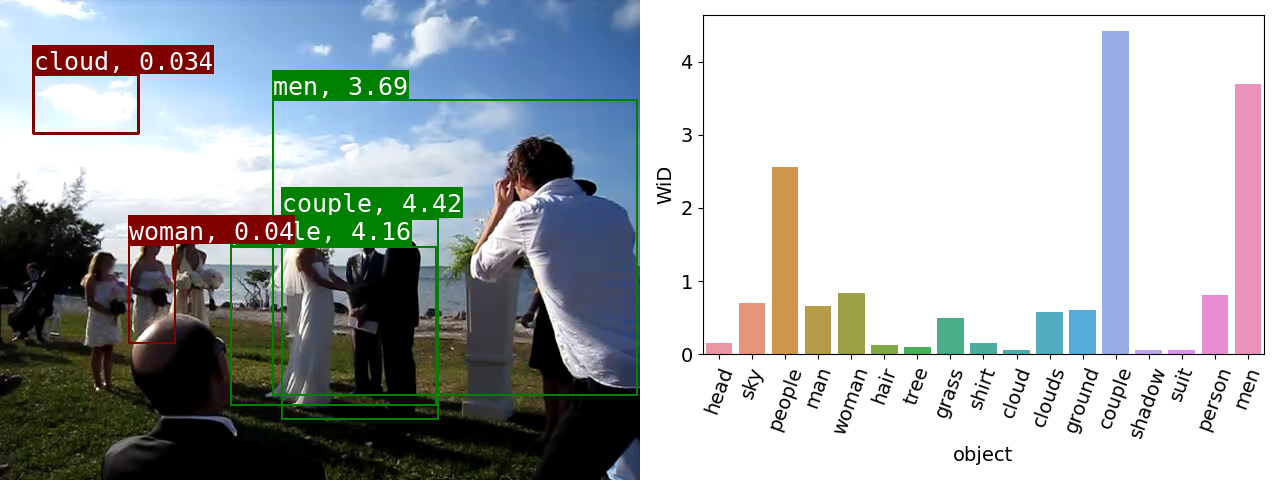
|
|
AC-SUM-GAN for Unsupervised Video Summarization. This is an implementation of our latest video summarization method, presented in our paper "AC-SUM-GAN: Connecting Actor-Critic and Generative Adversarial Networks for Unsupervised Video Summarization", IEEE Trans. on Circuits and Systems for Video Technology (IEEE TCSVT), vol. 31, no. 8, pp. 3278-3292, Aug. 2021. This is, to date, our most complete and best-performing method for video summarization. - Related publications [csvt21] - Software package [download source code] | 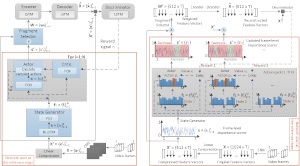
|
|
Structured Pruning of LSTMs. We provide the code for our paper "Structured Pruning of LSTMs via Eigenanalysis and Geometric Median for Mobile Multimedia and Deep Learning Applications", Proc. 22nd IEEE Int. Symposium on Multimedia (ISM), Dec. 2020. This code can be used for generating more compact LSTMs, which is very useful for mobile multimedia applications and deep learning applications in other resource-constrained environments. - Related publications [ism20] - Software package [download source code] | 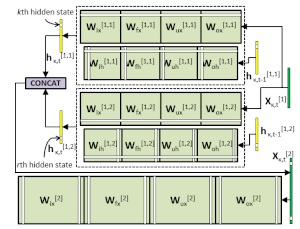
|
|
Video Summarization Evaluation: Performance over Random. We provide an implementation of our video summarization evaluation method presented in our publication "Performance over Random: A Robust Evaluation Protocol for Video Summarization Methods", Proc. 28th ACM Int. Conf. on Multimedia (ACM MM '20). This software can be used for evaluating automatically-generated video summaries using the Performance over Random (PoR) evaluation protocol. - Related publications [acmmm2020] - Software package [download source code] | 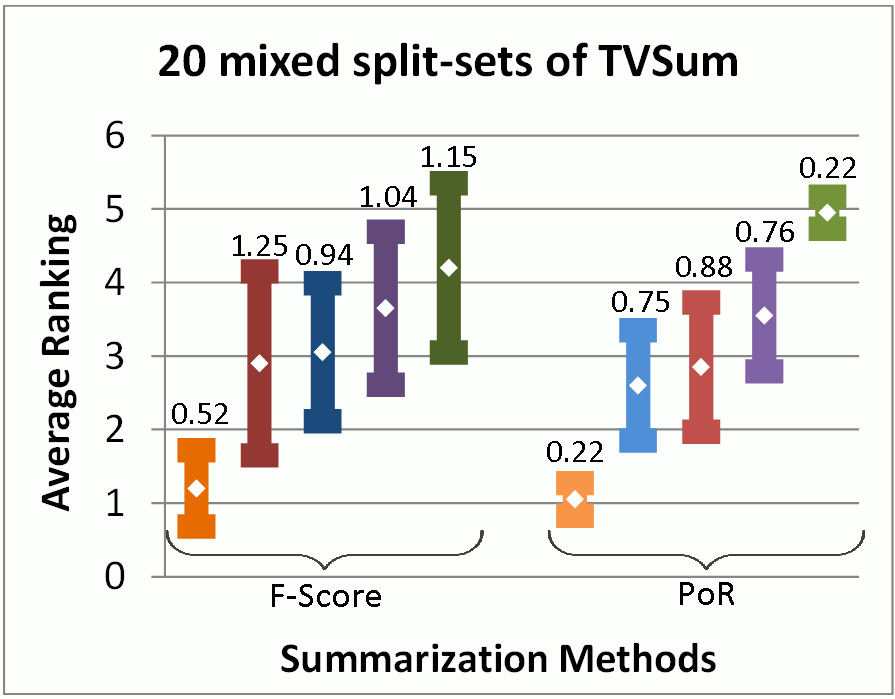
|
|
Dual Encoding Attention Network for ad-hoc Video Search. We provide an implementation of our extended dual encoding network for ad-hoc video search, presented at ACM ICMR 2020. This network makes use of more than one encodings of the visual and textual content, as well as two different attention mechanisms. - Related publications [icmr2020] - Software package [download source code] | 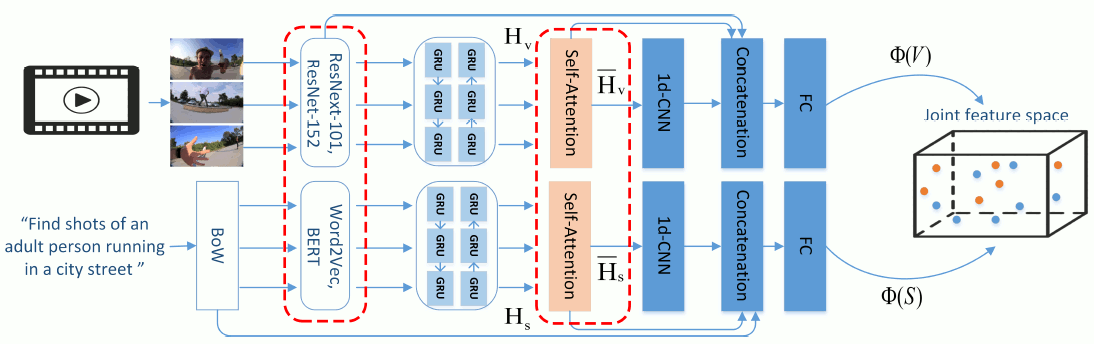
|
|
Fractional Step Discriminant Pruning for DCNNs. This is an implementation of our filter pruning framework for DCNNs, presented at the IEEE ICME 2020 Mobile Multimedia Computing Workshop. This framework compresses noisy or less discriminant filters in small fractional steps, utilizing a class-separability criterion and an asymptotic schedule for the pruning rate and scaling factor, so that the selected filters' weights are gradually reduced to zero. - Related publications [icme2020] - Software package [download source code] | 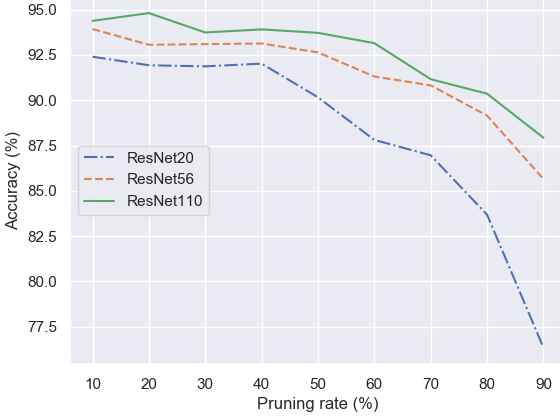
|
|
SUM-GAN-AAE for Unsupervised Video Summarization. We provide an implementation of the SUM-GAN-AAE deep learning architecture for automatic video summarization. This extends our previous SUM-GAN-sl architecture with an Attention Autoencoder, enabling the improved training of the overall model. Similarly to SUM-GAN-sl, this is an unsupervised learning method that is capable, after training, of producing representative summaries for unseen videos. - Related publications [mmm2020] - Software package [download source code] | 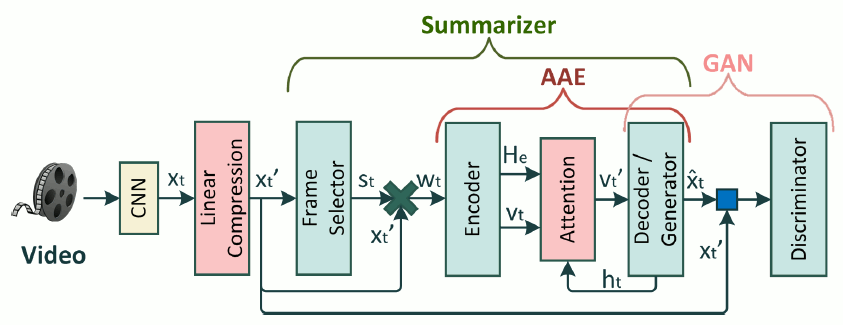
|
|
Subclass deep neural networks. This is an extension of deep convolutional neural networks for classification, which selectively introduces subclasses in the training of the model. Specifically, we provide implementations of the VGG16 and Wide ResNet architectures that include a new criterion for identifying the so-called "neglected" classes during the training of the network, and a novel cost function that extends the cross-entropy loss using subclass partitions for boosting the generalization performance of the neglected classes. - Related publications [mmm2020] - Software package [download source code] | 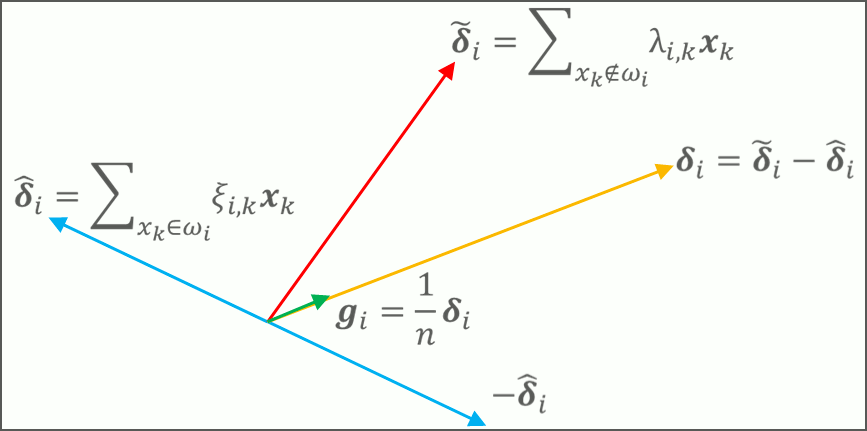
|
|
SUM-GAN-sl for Unsupervised Video Summarization. We provide an implementation of the SUM-GAN-sl deep learning architecture for automatic video summarization. Training is performed in a fully unsupervised manner without the need for ground-truth data (such as human-generated video summaries). After being trained, the SUM-GAN-sl model is capable of producing representative summaries for unseen videos, according to a user-specified time-budget about the summary duration. - Related publications [acmmm19] - Software package [download source code] | 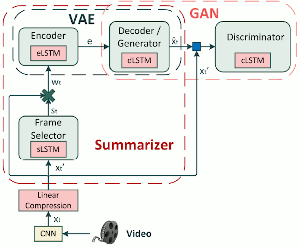
|
|
Fully convolutional deep networks in Keras. In this repository we provide an implementation of fully convolutional networks in Keras for the VGG16, VGG19, InceptionV3, Xception and MobileNetV2 models, for use in various image/keyframe annotation or classification tasks. We developed and used these deep networks in the context of assessing the aesthetic quality of images. - Related publications [mmm19a] - Software package [download source code] | 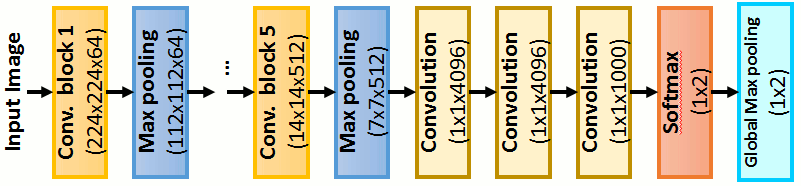
|
|
DCNN for Multi-Label Video/Image Annotation (FVMTL-CCELC). This is a DCNN architecture for video/image concept annotation that exploits concept relations at two different levels: i) implicit relations, by learning concept-specific representations that are sparse, linear combinations of representations of latent concepts, and ii) explicit relations, by introducing a new cost term that explicitly models the correlations between concepts. The complete DCNN architecture can be trained end-to-end with standard back-propagation. - Related publications [csvt19] - Software package [download source code] | 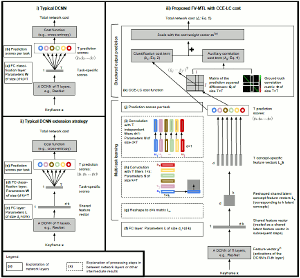
|
|
Support Vector Machine with Gaussian Sample Uncertainty (SVM-GSU). This is a novel maximum margin classifier that deals with uncertainty in data input; i.e., it allows each training example to be modeled as a multi-dimensional Gaussian distribution described by its mean vector and covariance matrix (the latter modeling the uncertainty), and defines a cost function that exploits the covariance information. Experimental results verify the effectiveness of this approach in various learning problems. - Related publications [pami18] - Software package [download source code] | 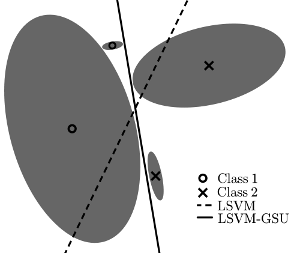
|
|
Incremental Accelerated Kernel Discriminant Analysis. This is a novel incremental dimensionality reduction (DR) technique, that offers excellent numerical stability and is specifically designed for use in incremental learning problems. Coupled with a linear SVM classifier, it offers state-of-the-art classification accuracy and an impressive training time speedup over batch AKDA (which is the current state-of-the-art) and also over traditional LSVM and kernel SVM (KSVM) methods. - Related publications [mm17a] - Software package [download software (~40MB zip file)] | 
|
|
InVID Verification Plugin. This web-browser plugin is developed as part of the InVID EU project, to help journalists verify videos on social networks. It allows to quickly fragment videos from various platforms (Facebook, Instagram, YouTube, Twitter, Daily Motion) and extract keyframes, to perform reverse image search on Google, Baidu or Yandex search engines, to collect contextual information for Facebook and YouTube videos, to enhance and explore keyframes through a magnifying lens, to perform advanced queries in Twitter, and to apply forensic filters on still images. - Related publications [mm17b] - Software package [download software] | 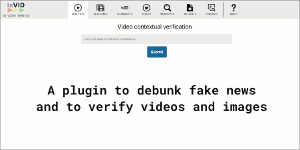
|
|
Accelerated Kernel Subclass Discriminant Analysis and SVM combination: An efficient dimensionality reduction and classification method, for very high-dimensional data. AKSDA is a new GPU-accelerated, state-of-the-art C++ library for supervised dimensionality reduction and classification, using multiple kernels. It greatly reduces the dimensionality of the input data, while at the same time it increases their linear separability. Used in conjunction with linear SVMs, it achieves SoA classification results, consistently higher than Kernel SVM approaches, at orders-of-magnitude shorter training times. AKSDA builds on our previous MSDA/GSDA/KMSDA methods. - Related publications [mm15] [mm16] (see also [tnnls13], [spl11] for more theoretical foundations) - Software package [download software] | 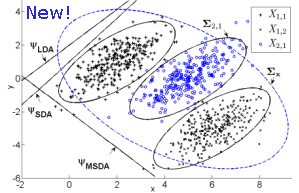
|
|
Image aesthetic quality assessment tools. This is a Matlab implementation of the feature extraction process for our Image Aesthetic Quality assessment method. Each image is represented according to a set of photographic rules, and five feature vectors are extracted, describing the image's simplicity, colorfulness, sharpness, pattern and composition. - Related publications [icip15] - Software package [download software] | 
|
|
Real-time video shot and scene segmentation. Software for the automatic temporal segmentation of videos into shots and scenes. The released software can detect both abrupt and gradual shot transitions with high accuracy, by jointly examining global and local image descriptors, and then also group the shots into scenes. The whole video analysis process is more than seven times faster than real-time-processing on an i7 PC, for the CPU version of the software. A GPU version is also available. - Related publications [csvt11] [icassp14] - Software package (v1.4.4, updated 10/4/2017) [download software] | 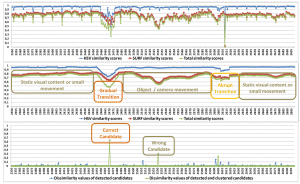
|
|
Mixture Subclass Discriminant Analysis (MSDA) & Generalized Subclass Discriminant Analysis / Kernel Mixture Subclass Discriminant Analysis (GSDA/KMSDA) software. MSDA is a dimensionality reduction method that alleviates two shortcomings of Subclass Discriminant Analysis (SDA). In short, MSDA modifies the objective function of SDA, and utilizes a partitioning procedure to help with the discrimination of data with Gaussian homoscedastic subclass structure. KMSDA is the kernel-extension of MSDA; GSDA is a speeded-up version of KMSDA. We provide, for non-commercial use, an MSDA and a GSDA/KMSDA implementation in Matlab code. - Related publications [tnnls13] [spl11] - MSDA software package [download source code] - GSDA/KMSDA software package [download source code] | 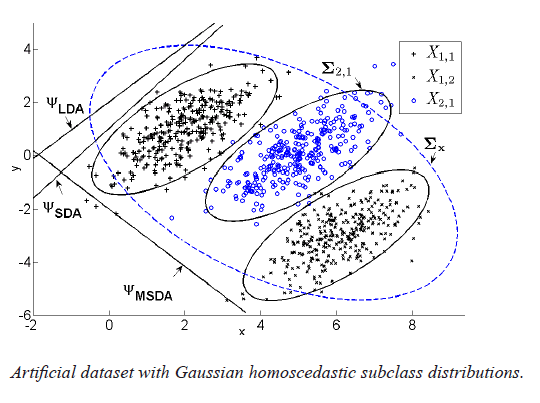
|
|
GPU-accelerated LIBSVM. We have developed an open source package for GPU-assisted Support Vector Machines (SVMs) training, based on the LIBSVM package. Kernel SVMs have gained wide acceptance in many fields of science, due to their accuracy. However, depending on the amount and nature of the training data, as well as on the cross-valitation approach that is followed for optimizing the SVM parameters, the training of SVMs in practise can often become prohibitively slow. The modifications we implemented to the well-known LIBSVM package revolve around porting the computation of the kernel matrix elements to the GPU, so as to significantly decrease the processing time for SVM training without altering the classification results compared to the original LIBSVM. - Related publication [wiamis11] - GPU-LIBSVM package (updated Oct. 2013) [download source code] - Short video (demo) [watch video] | 
|
|
Scene segmentation evaluation utility. We have developed a unidimensional measure for evaluating the goodness of video temporal segmentation to scenes. The developed measure is called Differential Edit Distance (DED). DED satisfies the metric properties, and is shown to be fast and effective in evaluating the results of scene segmentation methods and also in helping to optimize such methods' parameters. - Related publication [csvt12] - Scene segmentation evaluation utility [download software] | 
|